
We’ve been exploring the world of AWS AutoScaling Plans recently. Being captivated by the tasty-looking Predictive Scaling for EC2, we were wooed into replacing all of our AWS::AutoScaling::ScalingPolicy resources for equivalent, shiny new AWS::AutoScalingPlans::ScalingPlan resources.
These seemed great at first, but we ended up hitting a lot of gotchas with how AutoScalingPlans interact with AutoScalingGroups, particularly where CloudFormation was concerned.
TL;DR
This article will interest you if you’re considering moving to ScalingPlans and are a heavy user of AWS AutoScaling RollingUpdates. And hopefully save you some time and heartache.
You may also have ended up here because you’ve seen any of the below error messages as part of a CloudFormation update:
UPDATE_ROLLBACK_IN_PROGRESS
The following resource(s) failed to update: [AutoScalingPlan].
UPDATE_FAILED
Scaling plan has been updated but failed to be applied to all resources. Problems were encountered for 1 resource. See scaling plan resources for the failure details.And subsequently maybe also the following in the AWS AutoScaling console:
ActiveWithProblems
The resource was not updated because it was found to have different min/max capacity than what the scaling instruction indicatesRead on to find out more. Spoiler alert: there’s no happy ending.
Getting Started
On the face of it, moving to ScalingPlans seemed simple. We aren’t super-complicated people; we’d implemented TargetTracking policies on some of our services to track and add/remove instances in accordance with our AutoScalingGroup’s ASGTotalCPUUtilization metric. This old policy mapped perfectly to an equivalent ScalingInstruction TargetTrackingConfiguration property in the new resource. So we had feature-parity immediately.
Setting the PredictiveScalingMode to ForecastOnly allowed AWS Auto Scaling start to generate pretty looking graphs using Machine Learning™!
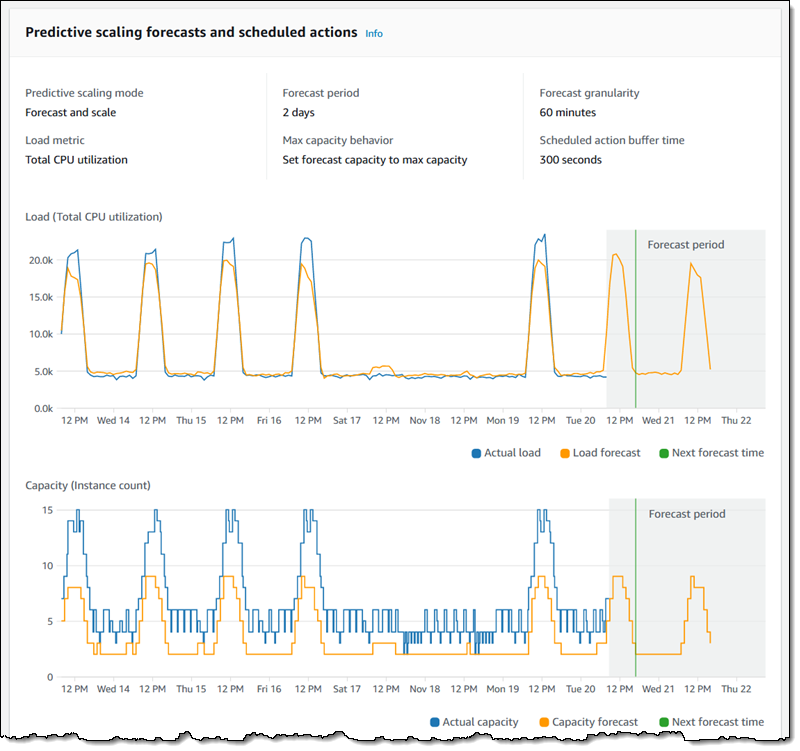
So, we set the PredictiveScalingMode to ForecastAndScale, basking in wonder at the dozens of AutoScaling ScheduledActions that were implemented on our AutoScalingGroup. Wow! Every hour, the size of the AutoScalingGroup would be enforced! You could even use the ScheduledActionBufferTime property to scale a set amount of time before the hour, in case you usually get really busy when the clock strikes 12, just like we do! Amazing!
For one reason or another, we went back to ForecastOnly. Our services are frequently victims to short, sudden, bursts of traffic. So the reality was that the capacity levels that AWS suggested was fine for regular traffic, but not enough if we saw an unexpected, unpredictable spike of traffic.
We just ended up setting our MinCapacity ever-higher until we were overprovisioned enough to deal with these spikes. This led to some ugly PredictiveScaling graphs — the blue line in the image above was continually flatlined above the orange line. A constant reminder of “wasted” compute.
So yeah, we turned predictive scaling off, thinking that we’d maybe enable it again sometime. We kept the new resources, because they were newer (hence better) and we still had the TargetTracking policies set up, so had feature parity, right? This was true, but we encountered some unexpected gotchas...
Changing AutoScalingGroup Capacity
We frequently want to change the size of our AutoScalingGroups. In production, we might scale up for a once-off event where we expect greater traffic. In our performance testing environments, we want to scale down at the end of the day to save money.
We also try to be good systems engineers. That means keeping our AWS infrastructure definitions within CloudFormation templates, for all the good reasons that entails (maintainability, reviewability, recreatability, etc).
So when implementing the new ScalingPlans, we did so by removing our old AWS::AutoScaling::ScalingPolicy CloudFormation resources and replacing them with AWS::AutoScalingPlans::ScalingPlan resources. The latter requires that you provide a MinCapacity and a MaxCapacity for the ScalingPlan to enforce upon the AutoScalingGroup:
"AutoScalingPlan": {
"Type" : "AWS::AutoScalingPlans::ScalingPlan",
"Properties" : {
<...snip...>
"ScalingInstructions" : [ {
"DisableDynamicScaling" : false,
"MaxCapacity" : <Integer>,
"MinCapacity" : <Integer>,
<...snip...>
}This looked familiar, as we also set MinSize and MaxSize on our AutoScalingGroup resource using a couple of CloudFormation Parameters:
"AutoScalingGroup": {
"Type": "AWS::AutoScaling::AutoScalingGroup",
"Properties": {
<...snip...>
"MinSize": { "Ref": "MinSize" },
"MaxSize": { "Ref": "MaxSize" },
<...snip...>
}We could just reuse those, implementing as so:
"AutoScalingPlan": {
"Type" : "AWS::AutoScalingPlans::ScalingPlan",
"Properties" : {
<...snip...>
"ScalingInstructions" : [ {
"DisableDynamicScaling" : false,
"MaxCapacity" : { "Ref": "MinSize" },
"MinCapacity" : { "Ref": "MaxSize" },
<...snip...>
}Now, to change the number of instances running, it should be as simple as adjusting the value of MinSize and MaxSize CloudFormation Parameters. Let’s do it!

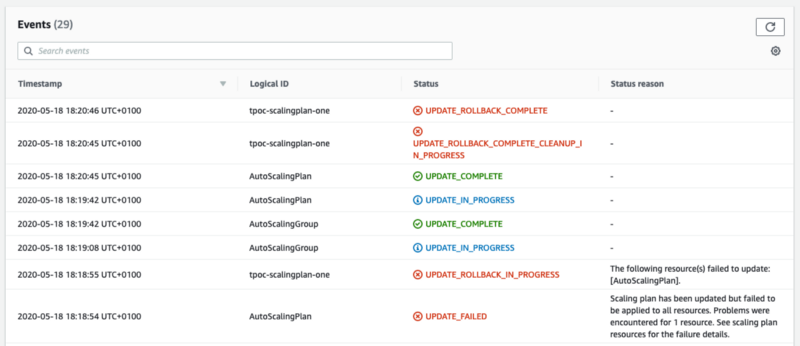
The above images show result of adjusting either of the shared MinSize or MaxSize CloudFormation parameter values and then performing a CloudFormation update. What happens seems to be the following:
- The AutoScalingPlan resource transitions into UPDATE_IN_PROGRESS.
- In the AWS AutoScaling console, the ScalingPlan reports that it is:
ActiveWithProblems — The resource was not updated because it was found to have different min/max capacity than what the scaling instruction indicates. - The AutoScalingPlan resource transitions into UPDATE_FAILED and the CloudFormation Stack begins to roll back.
- When the stack enters ROLLBACK_COMPLETE, the MinSize/MaxSize parameter you changed is set back to its original value. The size of the AutoScalingGroup also hasn’t changed.
This is not great — let’s see what AWS has to say on the matter in the Other Considerations in the Best Practices for AWS Auto Scaling Plans documentation…
Your customized settings for minimum and maximum capacity, along with other settings used for dynamic scaling, show up in other consoles. However, we recommend that after you create a scaling plan, you do not modify these settings from other consoles because your scaling plan does not receive the updates from other consoles.
Emphasis mine. If we go back to our CloudFormation Events above we can see that the AutoScalingGroup resource was updated by CloudFormation before the AutoScalingPlan resource was. That’ll be a modification from an “other console”, then.
Sound of Separation
OK, fine. It’s a bit messy, but we can use seperate CloudFormation parameters:
- AutoScalingGroupMinSize: MinSize of the AutoScalingGroup resource
- AutoScalingGroupMaxSize: MaxSize of the AutoScalingGroup resource
- AutoScalingPlanMinSize: MinCapacity of the AutoScalingPlan resource
- AutoScalingPlanMaxSize: MinCapacity of the AutoScalingPlan resource
We can’t omit any; MinSize and MaxSize are Required according to the AWS::AutoScaling::AutoScalingGroup documentation. Same deal for MinCapacity and MaxCapacity of AWS::AutoScalingPlans::ScalingPlan ScalingInstructions.
We’ll just set AutoScalingGroupMinSize and AutoScalingGroupMaxSize to 0, then scale up our service by adjusting AutoScalingPlanMinSize and AutoScalingPlanMaxSize. That works just fine.
At face value, this has fixed our issue. We can now adjust AutoScalingPlanMinSize and AutoScalingPlanMaxSize freely. This updates the size of the AutoScalingGroup without adjusting it via CloudFormation.

“And they all lived happily ever after”, right? Here’s where I tell you the follow-up story of how we’re heavy users of AWS AutoScaling RollingUpdates. When we deploy a new version of a service, it looks like this:
- We create a new Amazon Machine Image (AMI) which contains a new version of our application.
- We update our AWS::AutoScaling::LaunchConfiguration resource with this new AMI ID as part of a CloudFormation stack update. This forces a recreation of the LaunchConfiguration resource which in turn cascades an update to the AutoScalingGroup resource.
- Our AutoScalingGroup has an UpdatePolicy configured to perform RollingUpdates. Replacing the LaunchConfiguration triggers the replacement of each one of the AutoScalingGroup’s running instances, replacing the old instances with new instances. When the RollingUpdate is complete, so is our deployment.
RollingUpdates and ScalingPlans appear to co-exist, in that you won’t see a RollingUpdate fail. It’ll succeed just fine. Then, when next you come to adjust the size of your AutoScalingGroup via the AutoScalingPlanMinSize and AutoScalingPlanMaxSize parameters, CloudFormation will scream at you:
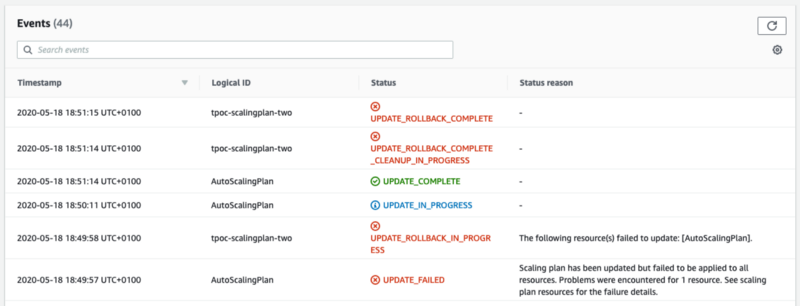
UPDATE_FAILED
Scaling plan has been updated but failed to be applied to all resources. Problems were encountered for 1 resource. See scaling plan resources for the failure details.
It’ll rollback immediately. If you’re quick, you’ll see the same status messages in the AWS AutoScaling console from when we tried using the shared MinSize/MaxSize parameters:
ActiveWithProblems — The resource was not updated because it was found to have different min/max capacity than what the scaling instruction indicates.
What happened here? Well, during the first stack update where we performed the RollingUpdate, I observed the following:
- Before doing anything, Note the size of your AutoScalingGroup. It should match AutoScalingPlanMinSize and AutoScalingPlanMaxSize.
- Start a CloudFormation update that triggers a RollingUpdate (e.g. alter the AMI ID of the LaunchConfiguration). Watch it succeed.
- Note the size of your AutoScalingGroup at this point. You’ll notice that it has changed to match AutoScalingGroupMinSize and AutoScalingGroupMaxSize.
This is unexpected. And confirms that a RollingUpdate will reapply whatever properties your CloudFormation template’s AutoScalingGroup has set.
The next time you come along to adjust the capacity of your AutoScalingGroup (be that in five minutes or in five months) by adjusting AutoScalingPlanMinSize or AutoScalingPlanMaxSize, you’ll be set up to fail from the get-go.
As far as the AutoScalingPlan is concerned, your AutoScalingGroup has changed from underneath it. From an “other console”, as the Best Practices for AWS Auto Scaling Plans liked to put it.
The AutoScalingPlan is never updated about this change, and will never automatically fix itself. In practice, the only way to fix this is to either:
- Manually adjust the size of the AutoScalingGroup back to the same values as the last known adjustment that the AutoScalingPlan made.
or
- Delete and recreate the ScalingPlan resource.
(Note: when you do this, your AutoScalingGroup size will revert to AutoScalingGroupMinSize and AutoScalingGroupMaxSize.
Sure hope you hadn’t configured those as 0…)
Speaking as a guy who’s deleted a few dozen ScalingPlans to fix these issues, let me tell you that deleting them is what you’ll be doing most often.
Why? Well, while you can determine what the current size of an AutoScalingGroup is, and while you can determine what the current capacities of an AutoScalingPlan are, you cannot determine what an AutoScalingPlan thinks that the AutoScalingGroup should be set to. That information is not exposed to us mere mortals.
Conclusions
It’s a tale as old as time — new AWS services, existing AWS services and CloudFormation don’t always mix or fit tightly enough together. In this case, there’s a lack of integration between AutoScalingGroups and AutoScalingPlans, and an unreasonable expectation that AutoScalingPlans should be the only resources permitted to change the size of an AutoScalingGroup.
The root cause of our problem is that CloudFormation always rolls back. In reality, all we’d need to fix our issue is one additional property named ForceCurrentCapacity on an AWS::AutoScalingPlans::ScalingPlan ScalingInstruction resource. When true, the AutoScalingPlan could say: “yeah, I’m gonna enforce whatever my MinCapacity and MaxCapacity are on the AutoScalingGroup, regardless or not whether they seem to have changed”.
But we don’t have that. And instead, due to continued rollbacks while trying to adjust the size of our AutoScalingGroup resources following service deployments, we reluctantly went back to AutoScaling::ScalingPolicy resources. Although they’re not as fancy, they work without any real fuss and scale our services when we need it.
And while we don’t have the option of turning PredictiveScaling back on or seeing the pretty graphs that the AWS Auto Scaling console provides, I’ll take working deployments and predictable CloudFormation updates any day.